
.
Clustering is an unsupervised machine learning technique that divides the population into several groups or clusters such that data points in the same group are similar to each other, and data points in different groups are dissimilar.
Clustering is used to identify some segments or groups in the dataset.
Clustering can be divided into two subgroups:
(1) Hard Clustering.
In hard clustering, each data point is clustered or grouped to any one cluster. For each data point, it may either completely belong to a cluster or not.
K-Means Clustering is a hard clustering algorithm. It clusters data points into k-clusters.
(2) Soft Clustering.
In soft clustering, instead of putting each data points into separate clusters, a probability of that point to be in that cluster assigned. In soft clustering or fuzzy clustering, each data point can belong to multiple clusters along with its probability score or likelihood.
One of the widely used soft clustering algorithms is the Fuzzy C-means clustering (FCM) Algorithm.
.
.
.
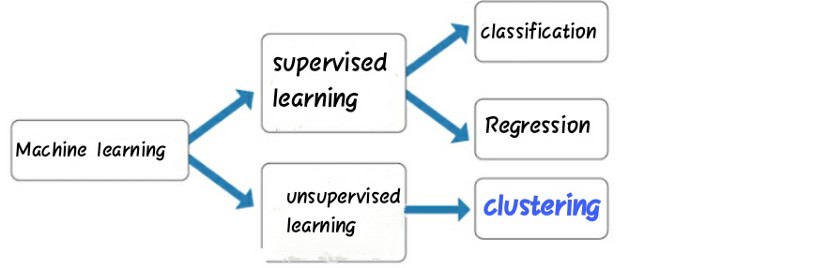
Clustering is a unsupervised Machine learning algorithm. In unsupervised learning , you have only input data and no output data. Unsupervised learning is used to find pattern in given data in order learn more about data.
.
https://medium.com/@codingpilot25/clustering-explained-to-beginners-of-data-science-e25d73c77a24
.
Cluster analysis or clustering is the most commonly used technique of unsupervised learning. It is used to find data clusters such that each cluster has the most closely matched data.
.


No comments:
Post a Comment